概览
- 了解编译原理,对现代编译器compiler设计有所了解
- 介绍dart编译器设计, 工程实践上如何设计和实现
- 了解dart编译器核心代码流转: 核心代码、主要优化
Dart编译器架构设计
现代编译器基本分成两个部分
Frontend(编译器前端):对源代码分析得到AST(抽象语法树)以及符号表,并完成静态检查Backend(编译器后端):基于 AST/IR等前端产物,生成平台目标代码
编译架构
在dart中,这两部分具体工作:
cfe前端编译: dart代码输入, 通过词法、语法分析,构建一颗ast(compoent)树,在经过一系列的优化(treeshake、tfa、Desugaring),将优化后的ast树二进制写入到dill文件中后端编译链路: dill作为输入,重建ast树,再将ast树转化为中间FlowGraph, 经过FlowGraph中一系列的平台无关优化,根据编译目标生成JIT或者机器码
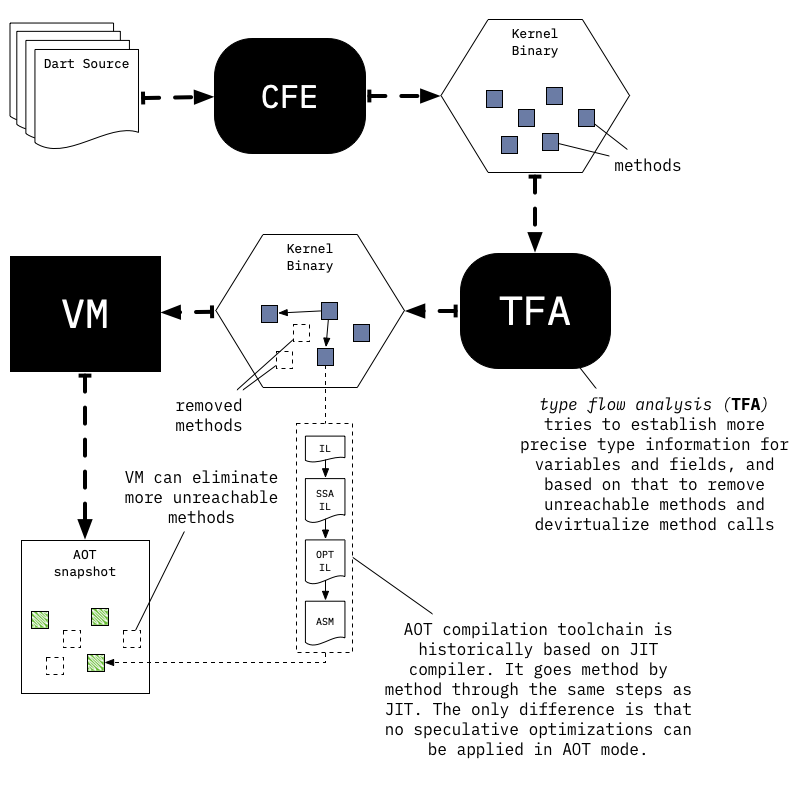
编译模式:
- __JIT 模式__:
!defined(DART_PRECOMPILED_RUNTIME) - __AOT 模式__:
defined(DART_PRECOMPILED_RUNTIME) - 模拟器模式:
USING_SIMULATOR, Dart 虚拟机将以 CPU 模拟器的方式工作,逐条执行 JIT 编译出来的机器指令。
编译产物
- snapshot: 适用 Dart 编译器和 Flutter Tools (JIT 或 Kernel)
- elf: 适用 Android AOT
- assembly: 适用 iOS AOT
前端编译链路CFE
简化流程代码
1 | //pkg/frontend_server/lib/frontend_server.dart |
- 根据输入文件,进行词法、语法分析
- 构建ast树: 第一次构建ast主题元素, 第二次构建完整ast
- 运行各种优化:语法糖脱糖(eg async) 、 CFE 阶段最重要的2个优化 Tree-shaking和tfa
- 将优化后的ast树二进制写入dill文件中
词法分析
1 | int Add(int a, int b) { |
分词产生token, 源码位置pkg/_fe_analyzer_shared/lib/src/scanner
1 | int offset:0, false |
语法分析
语法分析结果输出. 源码pkg/_fe_analyzer_shared/lib/src/parser
1 | Procedures: [Add, main] |
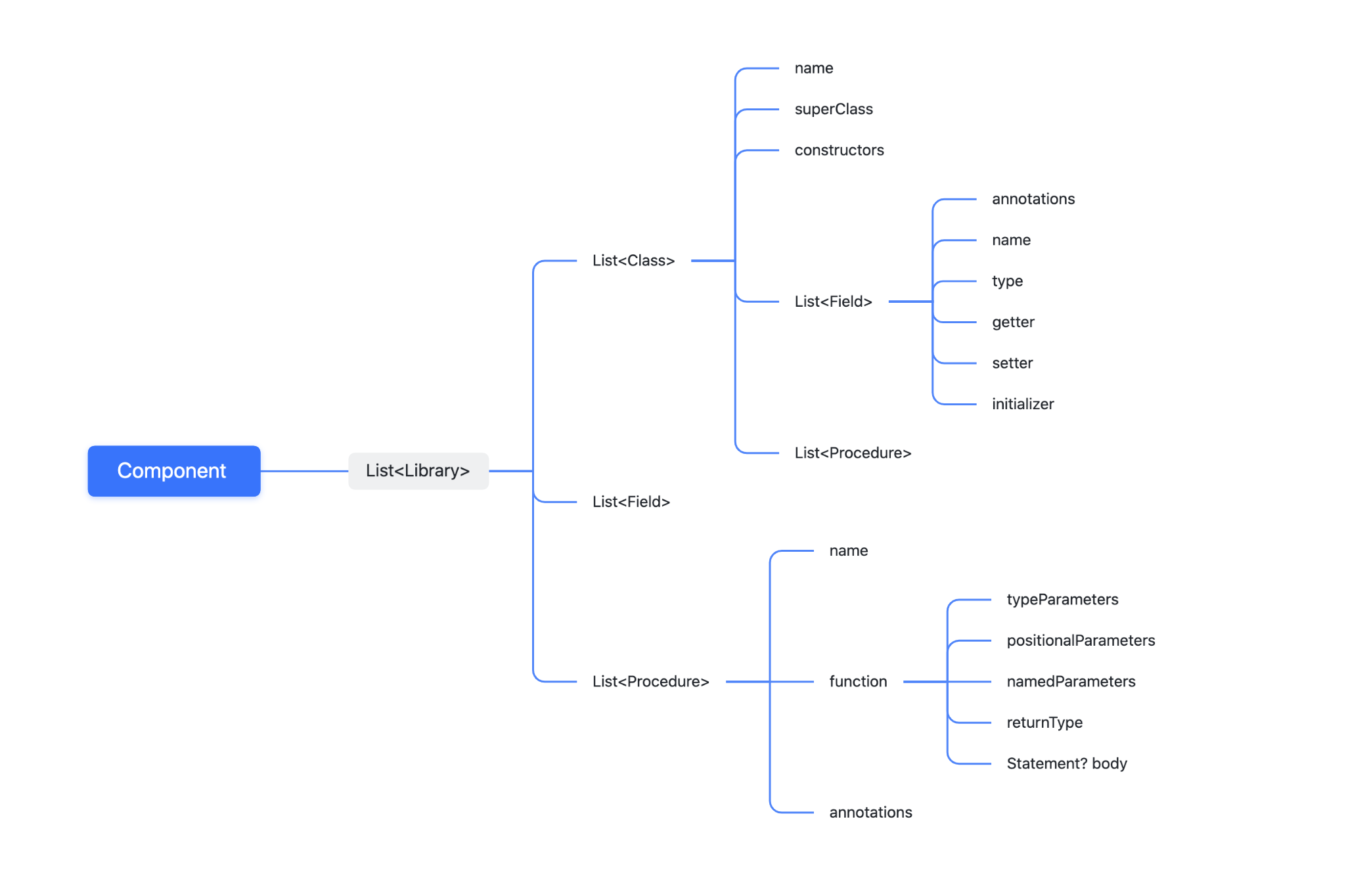
AST树构建
- 构建ast outine, 构建顶层元素: lib、class、filed、 函数体(procedure)节点本身(函数内容不处理)
- 完整ast构建: 处理函数体procedure内容, 即函数内部逻辑的ast
ast树的结构如下
前端编译优化
在pkg/kernel/lib/transformations/下有各种优化,runCompiler 函数传入 --aot 选项开启这些优化。
Desugaring语法脱糖: 比如将 async/await转换成基于 Future 实现Tree-shaking: 从 kernel 产物中摘除未使用的 procedures、fields、classes,TFA优化: 全局分析类型流,并进行一些优化工作(比如简化参数传递)
AST序列化为dill
函数入口
1 | // import 'package:front_end/src/fasta/kernel/utils.dart' |
dill文件格式如下
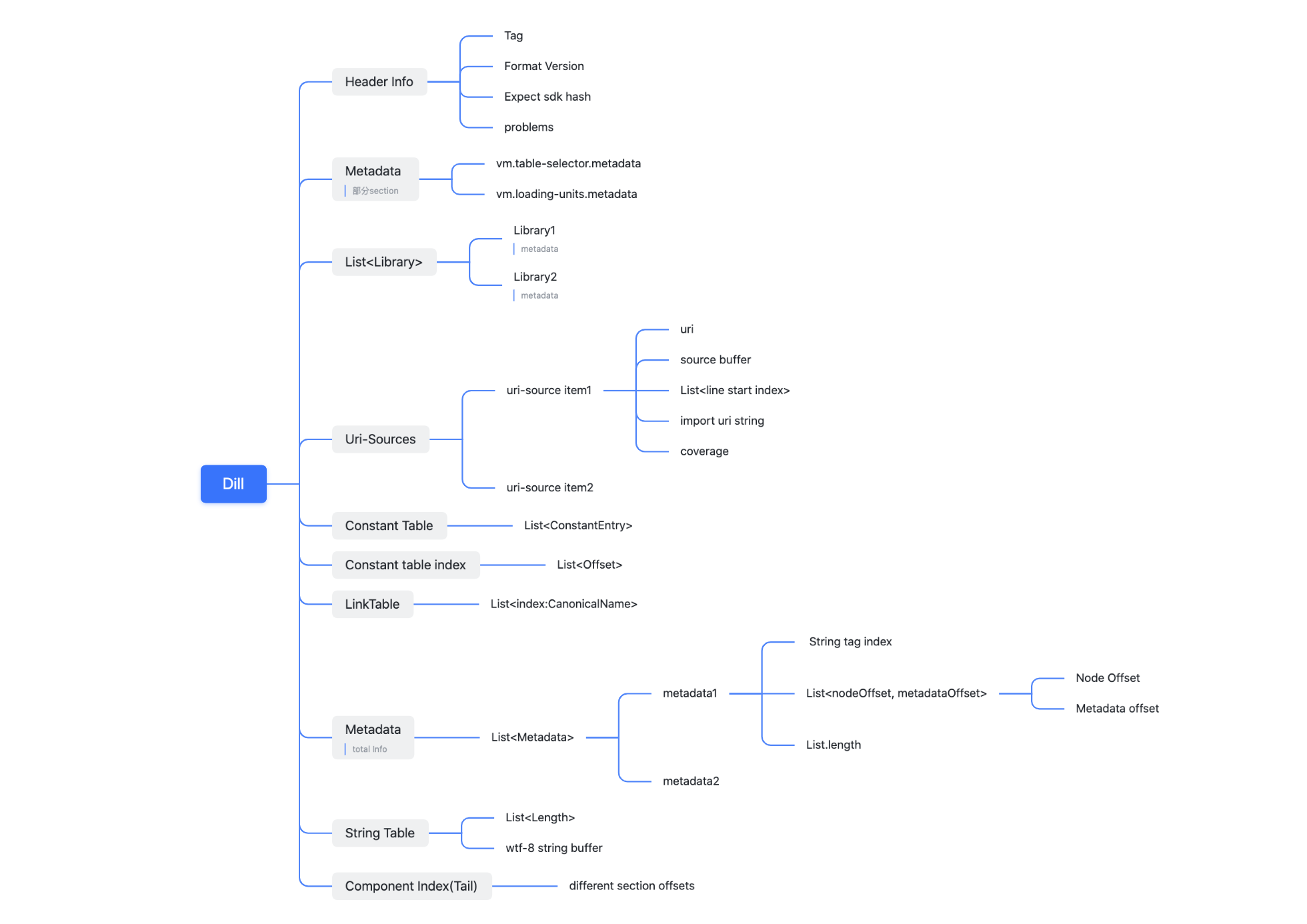
Headerinfo: 包含一些版本信息、hash、tagMetadata: 大部分是基于TFA(type flow analysis)分析后产生vm.call-site-attributes.metadata: 一般用于接口型对象进行调用的时候注明实际调用对象的类型vm.direct-call.metadata: 就是通过分析可以确认不存在虚函数调用的情况可以直接转为基于特定类型的调用vm.table-selector.metadata: 用于生成dispatch table, 每个selector自身的index对应selector编号 (虚函数调用)vm.loading-units.metadata用于注明加载单元的信息. id和lib uri
Uri-source: 记录到源码的映射 (行号、offset)Constant table+ ````Constant table index```- 常量表: 基本组成格式是 “ConstantTag”+”Constant value”
- 常量表索引: 对应于常量表每个条目在文件中的位置。
LinkTableStringTable:字符串常量表ComponentIndex: 记录上述section的index和全局信息
后端编译链路 GenSnapshot

入口gen_snapshot
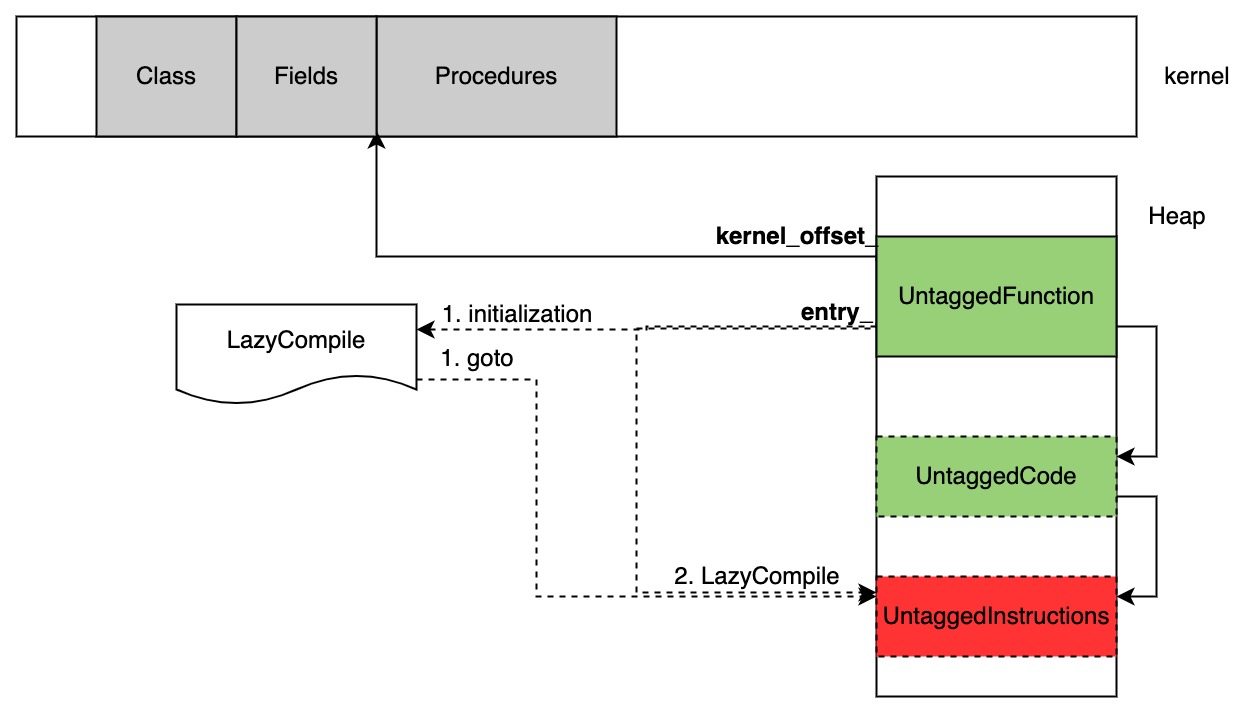
- 加载kernel序列化ast: 处理元数据部分:包含所有 Class 和顶层 Procedure(即function),,内部ast不处理,设置为lazycompile, 用offset记录
- 编译函数体,转化成中间指令表示IL : 从main函数(LazyCompile)开始, 编译直接/间接被 main 函数调用的其他函数,,得到
FlowGraph,即IL中间指令 - 平台无关指令优化 : 调用
CompilerPass::RunPipeline执行一系列平台无关的优化,以求最终生成性能和体积俱佳的机器指令 - 指令编译为机器码 : 将IL指令编译为具体平台的汇编(x86、x64、arm)
- 将机器码序列化到文件中: elf、snanshot、assembly
kernel加载过程
Program 类封装 kernel,再经由KernelLoader工具类LoadLibrary 方法还原成 Library 对象(包含所有 Class 和顶层 Procedure)
加载完成后,生成ast树, 之后编译器会将ast转化为IL表示
IL定位是编译器通用设计中中间指令IR的概念, 类似于llvm或者kotlin compiler中的IR.
IL介绍
compiler pipeline 首先通过 FlowGraphBuilder 把kernel转换成 FlowGraph. 即IL. IL本质上是一种线性结构,它由一系列基本的指令(Instruction)组成,表示一个函数的运行过程. 一个或多个指令按顺序排列在一起,构成一个块(Block)。块的最后一条指令可能是一个跳转指令(包括条件跳转和无条件跳转),指向其他块;或者是一条Return指令,表示退出函数。
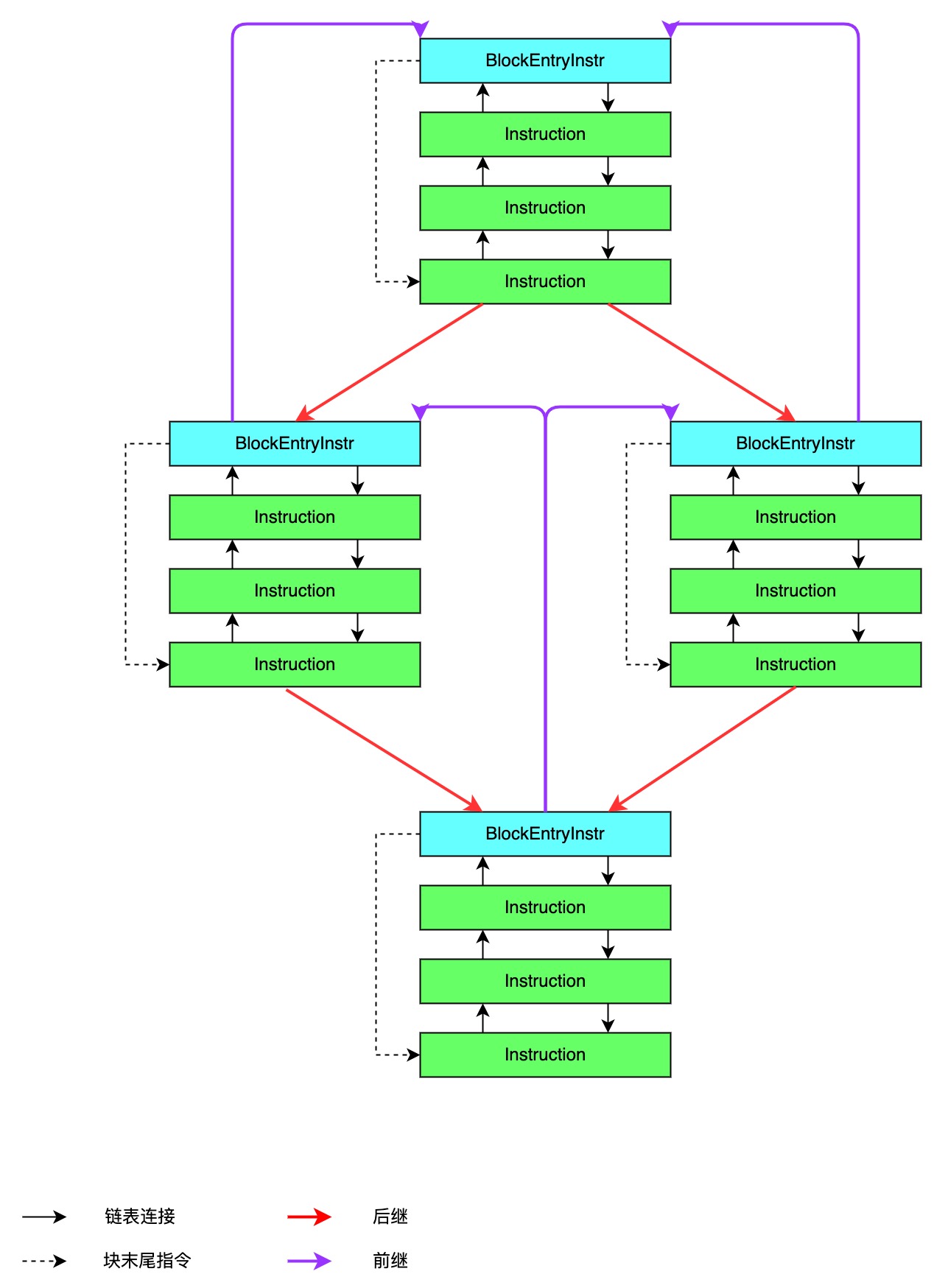
Instruction指的是非BlockEntryInstr的子类, BlockEntryInstr分为好几种类型:(这一套机制主要作用是用来做流分析和优化工作的,做一些限制可以简化分析过程)
- GraphEntryInstr: 任何一个函数的起始都是一个GraphEntryInstr,不包括任何实际机器码.拥有一到三个后继,每一个后继都是函数的一个入口点,包括:
- normal entry:函数正常入口点,这个入口点是每个函数都具备的。
- unchecked entry: 未检查入口点,从这个入口点进入,会首先执行检查参数类型代码,然后再执行函数体,这个入口点是可选的。
- osr entry: OSR=on stack replacement 入口点是可选的。
- FunctionEntryInstr: 函数入口点,normal entry和unchecked entry都是这个类型
- OsrEntryInstr osr entry: osr entry入口点是这个类型
- JoinEntryInstr: 无条件跳转指令目标块,多个不同块的无条件跳转指令跳转到同一个JoinEntryInstr是允许的。(类似goto的label)
- TargetEntryInstr: 条件跳转指令的目标块 (类似if else)
- CatchBlockEntryInstr: catch语句块
IL优化
编译器得到 FlowGraph 后,调用 CompilerPass::RunPipeline 执行一系列平台无关的优化,以求最终生成性能和体积俱佳的机器指令
1 | // compiler_pass.cc |
- ConstantPropagation 常量传播与折叠优化
- Inlining(函数内联优化)
- CallSpecializer (函数调用特化)
ConstantPropagation(常量传播与折叠优化)
demo
1 | ConstProp() { |
未优化 IR:
1 | dart --print_flow_graph abc.dart |
优化ir
1 | dart --print_flow_graph_optimized --print-flow-graph-filter=ConstProp --optimization_counter_threshold=1 --no-background-compilation abc.dart |
Inlining(函数内联优化)
1 | int Add(int a, int b) { |
未优化ir
1 | dart --print_flow_graph add.dart |
优化ir
1 | dart pkg/vm/bin/gen_kernel.dart --platform vm_platform_strong.dill --tfa --aot -o add.dill add.dart |
IL生成机器码
FlowGraph 经过众多 Pipeline 优化后交给 CompilerPass::GenerateCode 生成机器指令,GenerateCode 通过 FlowGraphCompiler 类遍历 FlowGraph 所有指令块 Block,每个 Block 包含若干条 Instruction,每条 Instruction 可以生成(lowering)相应的若干条机器指令
1 | // flow_graph_compiler.cc |
CallSpecializer 指令生成阶段(x64平台):
1 | // il_x64.cc |
在代码生成最后的阶段,针对当前编译的函数,虚拟机创建相应的 Instructions 对象和 Code 对象,为机器指令分配可执行内存,最后 Attach 到 Function 对象,设置 entry 属性。
1 | // object.cc |
代码序列化
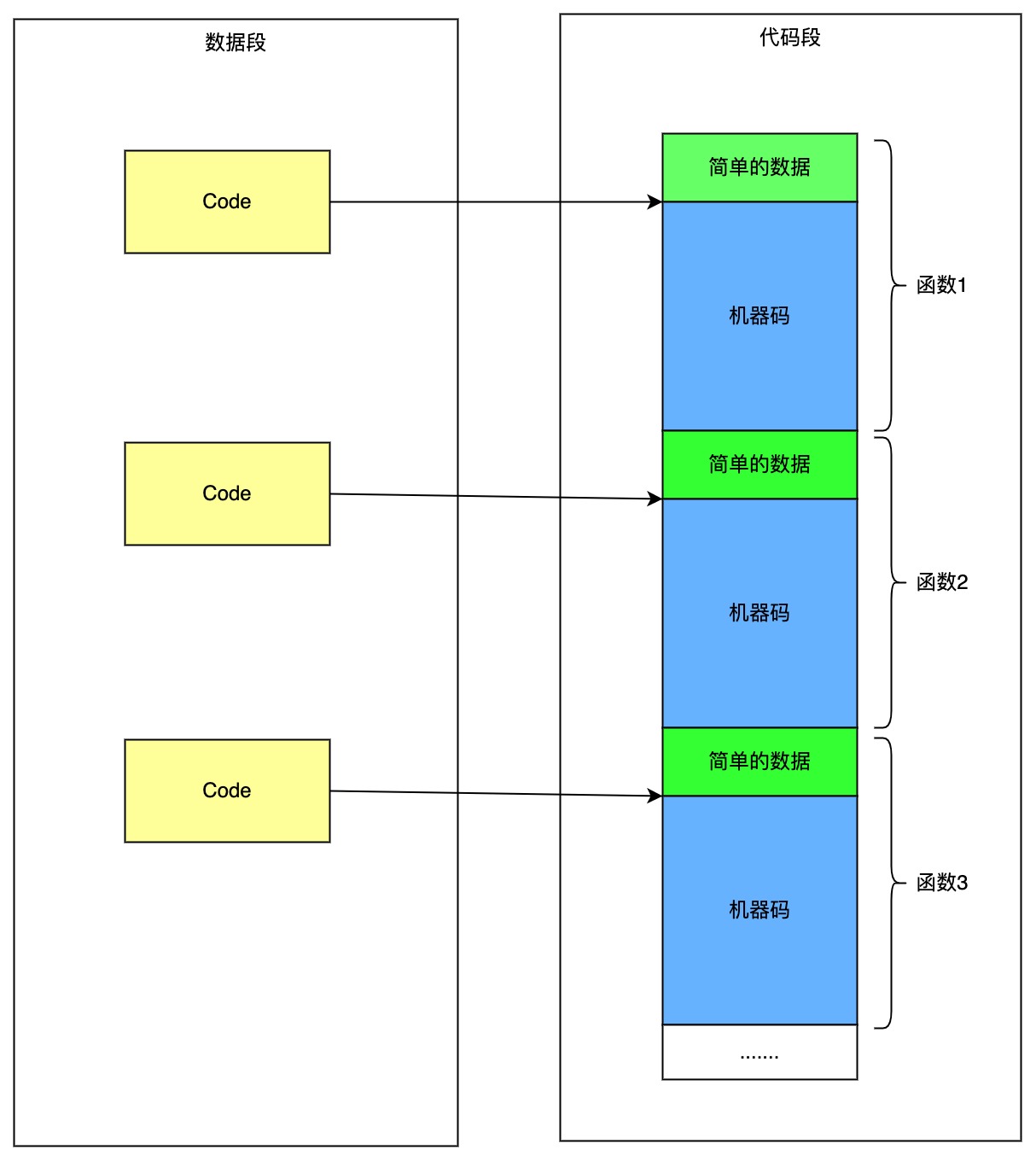
编译后的代码分成两部分:
- 数据段: 存储一些静态变量、类信息,虚拟机只read这部分数据.
- 代码段: 机器码运行指令Instruction,即机器码运行指令(x86、x64),虚拟机excute需要可执行权限.
AOT产物(app.so)中,数据段存在于 _kDartVmSnapshotData、_kDartIsolateSnapshotData.代码段存在于_kDartVmSnapshotInstructions、_kDartIsolateSnapshotInstructions
为了运行机器码,运行时必须掌握每一段机器码Instruction的内存位置。因此,在数据区必须记录机器码的位置信息。记录机器码位置信息的对象是Code对象。所以总体的数据格式大致如下
Code对象与记录机器码位置有关的主要成员有以下两个:
- entry_point_ 记录Code对象对应的机器码在内存中的位置
- instructions_: Instructions类型的对象,指向包含机器码的Instructions对象 (还有monorphic_entry_point_等其他三个)
数据段序列化
数据段主要格式如下
- Header数据区: 存储一些校验、版本、feature等等额外信息
- 对象数据区: 存储真代码相关的信息: 类型信息、字符串等等
Header数据格式
对象数据区数据格式
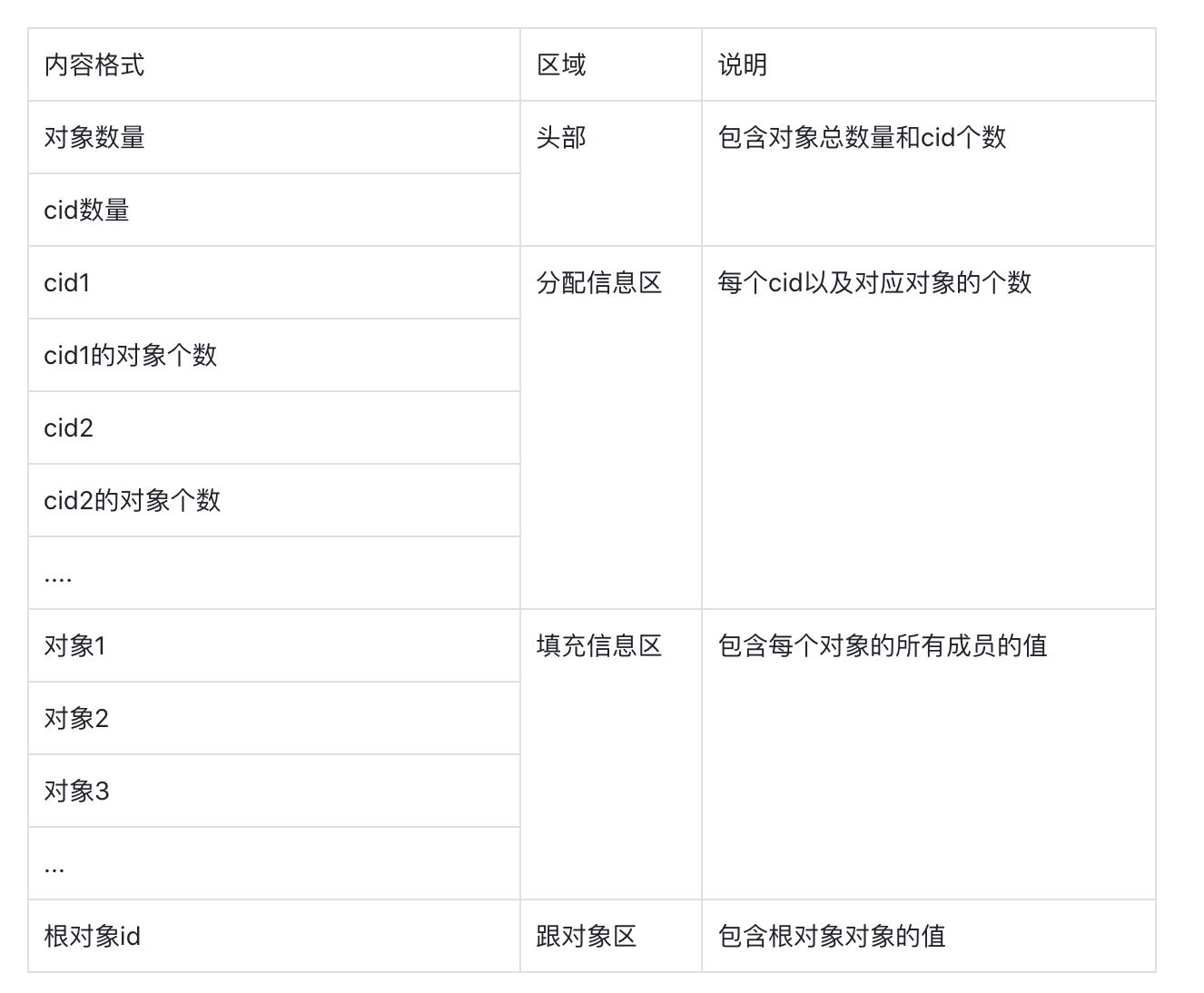
对象序列化的并不复杂, 如果想要序列化对象A:
- 收集到A直接或间接引用到的所有对象(包括A)
- 为每个对象分配一个id
- 将所有对象按id顺序序列化到流中,序列化数据应包括对象的类型(以cid表示)和对象的每一个成员。对于引用类型的成员,以被引用对象的的id代替。
- 序列化A的id到流的末尾。
| 字段 | 长度(字节) | 备注 |
|---|---|---|
| magic | 4 | 0xdcdcf5f5 |
| length | 4 | Snapshot数据总长度 |
| kind | 8 | 值为下列数值之一: FullFullCore/FullJIT/FullAOT/None/Invalid,在AOT模式下,kind的值总是FullAOT |
| version | 32 | 32字节长的hash字符串(无终结符)。其hash值依据下列文件内容计算:app_snapshot.h snapshot.cc object.cc …. |
| length | n | feature字符串(以0为终结符)。其内容包含: 编译版本、vm全局选项、isolate group选项(enable_asserts) 、abi信息、指针压缩选项、null-safety选项 |
Serialize方法的实现核心为代码,大致分为以下几步:
- 添加基础对象,并为基础对象分配id
- 根据根对象搜索所有需要被序列化的对象,按cid(class)分类,放入对应的SerializationCluster中
- 写入头部区 : 对象个数、instructions table的长度、cluster数量等等
- 为被序列化对象分配id,并写入分配信息区
- 写入填充信息区: 写入分配好的序列化详细信息
- 写入根对象区
1 | void Serializer::Serialize(){ |
机器码序列化
Code对象和机器码的关系至少有两种:
- Code对象以instructions_成员持有Instructions对象,entry_point_指向Instructions中的机器码位置
- Code对象不持有Instructions对象引用(instructions_成员为空),entry_point_指向代码段中的机器码位置
在JIT模式下,以及在AOT编译阶段,机器码显然保存在分配自堆中的Instructions对象中; 在AOT模式下, Code对象本身会被序列化到数据段中,其中entry_point_以对应机器码相对于代码段的偏移量代替
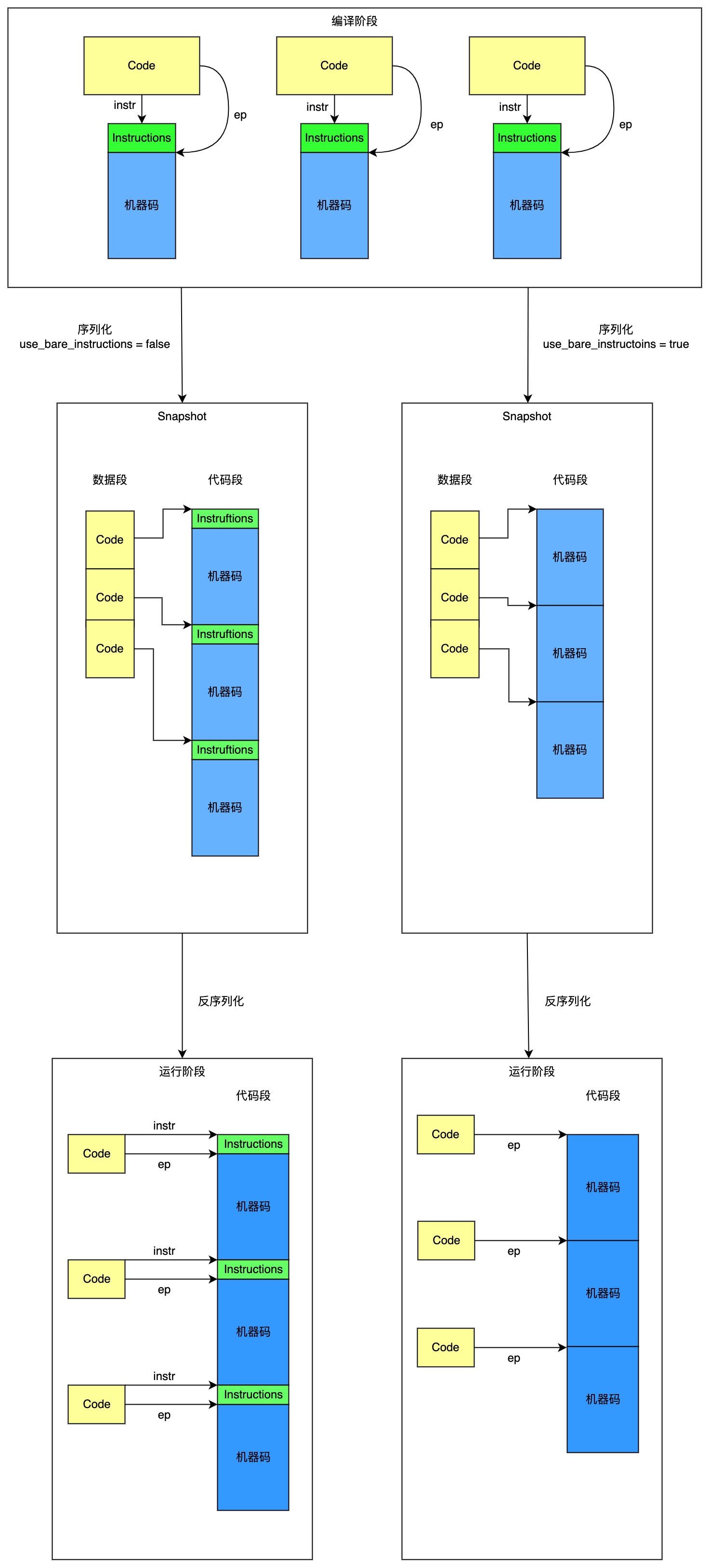
序列化过程
- 按正常流程序列化Code对象中除Instructions和entry_point_之外的其他信息
- 把Instructions对象序列化到代码段,可以序列化整个Instructions对象,或者只序列化机器码部分。
- 得到Instructions对象在代码段中的偏移量,在Code的填充信息区记录该偏移量
序列化过程中的一些细节:
- dedup优化: 如果发现两个或者多个函数的机器码完全一样,删除多余的机器码,公用同一份机器码
- instructions table: 根据PC寄存器的值反查当前Code对象. 将所有Code对象搜集为一个列表。为了提高搜索效率,要求Code对象按照其机器码的内存位置的顺序排列,以便采用二分法高效搜索。 dedup优化的存在打破了以上的前提,Code对象的序列化顺序不再和机器码顺序严格一致。为此,在序列化之前,还需要做一个排序操作,让共享同一份Instructions对象的Code对象排列在一起
- 基于pc相对位置的函数调用: 在AOT模式下,为了提高运行效率,对静态函数调用会采用基于pc相对位置跳转的方式.在序列化之前,机器码在代码区的布局还没有确定, 在编译时需要写入一个假的偏移量,序列化过程中需要计算真实的偏移量去替换。
机器码序列化/反序列化的主要相关类是CodeSerializationCluster和CodeDeserializationCluster。
- 跟踪引用时记录Code对象
1
2
3
4
5//1. Code序列化第一步,仍然是在跟踪引用时记录Code对象。
odeSerializationCluster::Trace()
//2. 在写入头部区之前,需要处理机器码排序、pc相对位置重定向等操作
instructions_table_len_ = PrepareInstructions();
//3. 分配信息写入 CodeSerializationCluster::WriteAlloc(Serializer* s)方法 - 在写入头部区之前,需要处理机器码排序、pc相对位置重定向等操作
1
2
3
4
5
6
7
8
9
10// Serializer::Serialize方法
int Serializer::PrepareInstructions(...){
//1. 机器码排序: 将共享同一个Instructions对象的Code排在一起
CodeSerializationCluster::Sort(code_cluster_->objects());
//2. 处理pc偏移量调用重定向
//据Code列表计算机器码布局
RelocateCodeObjects(vm_, &code_objects, &writer_commands);
//记录机器码布局, 后续序列化使用
image_writer_->PrepareForSerialization(&writer_commands);
} - 写入分配信息
1
2
3
4
5
6
7// CodeSerializer::WriteAlloc(Serializer* s, CodePtr code)方法
// 为Code对象分配id
s->AssignRef(code);
const int32_t state_bits = code->untag()->state_bits_;
// 写入Code对象的state_bits标记
s->Write<int32_t>(state_bits); - 写入填充信息done
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29CodeSerializationCluster::WriteFill(){
// 写入机器码
s->WriteInstructions(code);
// 写入object pool的引用
WriteField(code, object_pool_);
//写入其他Code关联对象引用
WriteField(code, xxx);
}
// 首先获取Instructions对象在代码区的偏移量。
// GetTextOffsetFor方法会将instr对象添加到一个列表,并计算其在代码区的偏移量。如果已经
// 添加过,则直接返回其在代码区的偏移量。注意,use_bare_instructions模式下,由于在pc
// 偏移量调用重定向过程中已经决定了代码布局,Code对象已经被添加进列表,此时总是返回其偏移量
// 即可
void Serializer::WriteInstructions(){
// 在use_bare_instructions模式下,对每个Code对象,序列化其相对于前一个Code对象在
// 代码区的偏移量之差。另外序列化其unchecked偏移量和单态标记。
if (FLAG_precompiled_mode && FLAG_use_bare_instructions) {
delta = xxx
WriteUnsigned(delta);
WriteUnsigned(payload_info);
return;
}
// 非use_bare_instructions模式下,直接序列化机器码偏移量和unchecked偏移量
Write<uint32_t>(offset);
WriteUnsigned(unchecked_offset);
}