涉及知识
- JVM内存模型
- Java并发
- JVM加载类以及初始化过程
单例的三个要素:
- 懒加载
- 线程安全
- 序列化与反序列化
Java中单例正确的三种写法
- volatile + doubleCheck
- SingletonHolder
- Enum
doubleCheck + volatile 关键字
理论上可行的 doubleCheck写法
1 | public class Singleton{ |
doubleCheck的思路:
假设有ABC三个线程,开始执行。
- 第5行为空,执行第6行。
- 假设AB两个线程,此时都走到了第6行,再假设A线程跑的比谁都快先执行了第6行。此时,B线程在第6行线程等待。
- A线程在第7行,instance为空,执行第8行,初始化instance,释放锁,到12行.
- B线程获得锁,继续执行第7行,instance不为空,跳过执行12行。
- 假设C此时执行到第5行,判断不为空,直接12行返回,省去再次加锁的开销。
可以看到理论上的方法考虑的很全面,既能保证单例,又能省去重复加锁的开销。但是没有考虑到JVM实际上的的内存模型,这种单例是有问题的。
正确的写法是什么呢?只需要多加一个volatile关键字就可以了,后面说为什么。
1 | private static volatile Singleton instance; |
JVM内存模型
先盗用一张图,原bolg是 链接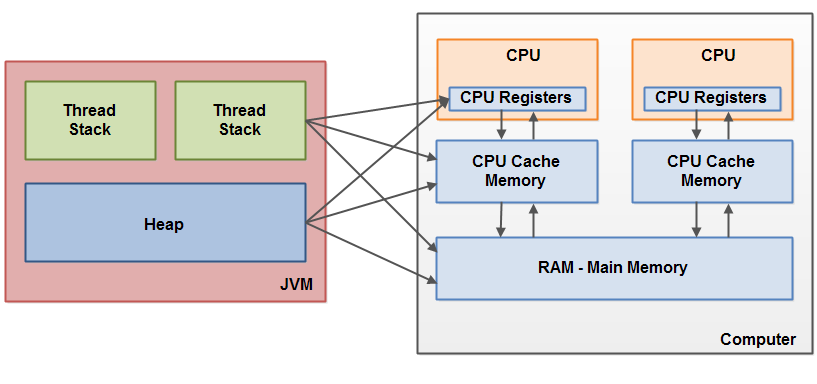
硬件层面
在计算机的硬件设计层面,CPU和主存(是指我们常说的多少G的内存这部分)和CPUCache以及cpu上寄存器速度差别很大,寄存器>CPUCache>>主存。CPU读取的时候优先寄存器,然后CPUCache然后主存,当访问同一个对象时,就会出现同步的问题。线程分配
现代计算机的CPU基本都是多核,所以可以在每个核心上跑个一个线程。假设JAVA程序中开了4个线程,可能这4个线程并行在跑。当这写线程访问一个共享数据时,是怎么处理的呢?对象在JVM上的分配
在JVM中,分为栈和堆,基本变量在栈上,对象实例在堆上。假设堆中有个对象Obj
1
2
3
4
5
6class Obj{
public int data=0;
pulic void add(){
data++;
}
}当AB两个线程同时访问Obj.add()方法时,会各自copy一份Obj的data到自己的线程栈中,进行++操作,拆解开来,分为
- 拷贝data
- 执行+1操作
- 写回data
JVM内存与硬件联系
上述操作对应到硬件层面- A线程对应的CPU核心从主存读取到Obj.data,缓存到cpuCace中,
- cpu执行+1操作,写回cpuCache。
- 在某个时刻,将cpuCache写回主存。
那么,问题就来了 - 在A线程所在的CPU未将cpuCache写回到主存时,主存上data还是0
- 假设线程B所在的CPU_B也执行add方法,则在A和B的CPU缓存中,data的值为1,主存中data的值为0.这明显与预期data=2不符合。
volatile关键字,在JVM规范中,对volatile域的写入操作happens-before于每一个后续对同一个域的读写操作。
volatile语义保证被修饰的变量被修改后,立马刷会主存,其它CPUCache发现被volatile关键字修饰的变量被刷回主存后,会重新从主存读取变量。
doubleCheck中volatile解释
回想一下doubleCheck中未加volatile时的情景。AB两个线程分别跑在CPU_A和CPU_B上。A创建了实例instance,但是有可能未将缓存刷新到主存上.B访问时,主存上的instance仍然为空,又构造了一遍,这就出问题了。加上volatile,问题解决。
优点:just work
缺点:太罗嗦了,同时没有保证单例的第三个特点 性序列化与反序列化 ,,或者说需要我们处理
SingletonHolder写法
1 | public class Singleton{ |
优点:简单而又优雅。
缺点:单例的第三个特点 性序列化与反序列化 没有保证
分析占坑
Enum写法
1 | public enum Singleton{ |
优点: 简单,同时,emum机制保证了3个特性
缺点:Android平台不推荐? 出处
Enums often require more than twice as much memory as static constants. You should strictly avoid using enums on Android.
分析占坑